|
|
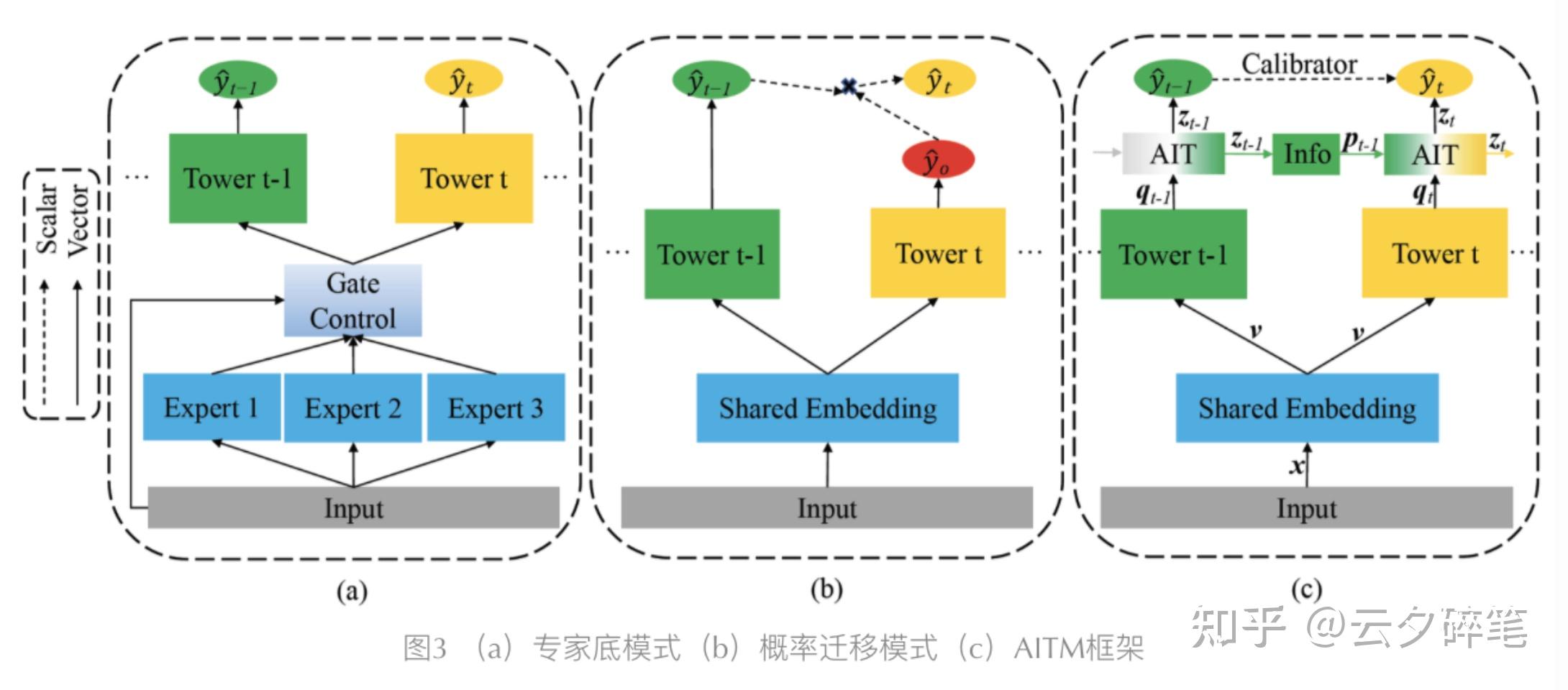
AITM模型是美团2021年提出来的多任务框架,与MMOE以及ESMM的架构有所区别。看的出来,MMOE在进行各个任务的预测时,各个任务在tower层后就独立进行输出了,联系主要在底层的专家网络和门控上。ESMM模式使用联合概率预测,但依然忽视了任务前后的关系。AITM的框架则考虑到前一任务对后一任务的影响,通过attention机制对前一任务的信息与当前信息进行加权,并输入给当前任务tower层,完成对当前任务的预测。这个想法看起来还是相当不错的。
下面基于torch_rechub的开源代码,对AITM模型进行学习。torch_rechub中实现了对特征的embedding转化,即EmbeddingLayer层。此处的实现细节可以参考其具体实现,具体作用就是将模型输入的特征转化为稠密低维的embedding向量,并将其拼接到一起,按照batch展平。得到的向量在代码里即为embed_x。此时embed_x向量维度为(batch_size,L),L为每个样本对应的embedding向量长度。
对每个任务,分别设置一个bottom层对数据进行压缩,bottom层由多层MLP构成。embed_x经过bottom层后,生成input_tower向量。将n各任务的input_tower向量放在一个list里,即为input_towers。input_towers为第i个任务的input_tower向量。input_tower向量的维度为(batch_size,bottom_dims[-1])。
对于第一个任务,直接将得到的input_tower向量输入到Towers层第一个Tower,得到任务1的概率预测值y1。对后续每个任务,将前一个任务的input_tower向量输入到info_gate层(n个任务有n-1个info_gate,每个info_gate由多层MLP构成),也就得到了info向量。info向量的维度为(batch_size,1,bottom_dims[-1])。
对当前任务,对当前任务的input_tower向量进行unsqueeze,并与得到的info向量拼接,得到向量ait_input,向量维度(batch_size,2,bottom_dims[-1])。
通过AIT注意力层,计算出info和input_tower各自的权重,并得到新的input_tower。假设info的权重为a,input_tower权重为1-a,则新的input_tower向量可以表示为a*info+(1-a)*input_tower(在注意力层中,将1维处理掉了,最后向量维度仍为(batch_size,bottom_dims[-1])。这也是为什么图中的框架里,对后续的任务,都会经过AIT后,才得到对应任务的概率预测值,以及当前任务的info实际上也是用的前一个任务经AIT层后更新的input_tower向量计算而来。
这就是原文的大体实现思路,torch_rechub的实现还是蛮清晰的。原文里的特征压缩都采用的多层MLP,特征交叉的工作基本直接交给DNN了,没做特别的处理。这一块是我们后续工作时可以优化的点。比如一个想法是对bottoms层进行改进,在进行数据压缩时就利用AutoInt里Interacting Layer层的特征交叉思想,对特征进行加权(不过这个需要将特征都转化为相同长度的embedding向量)。
import torch
import torch.nn as nn
from ...basic.layers import MLP, EmbeddingLayer
class AITM(nn.Module):
def __init__(self, features, n_task, bottom_params, tower_params_list):
super().__init__()
self.features = features
self.n_task = n_task
self.input_dims = sum([fea.embed_dim for fea in features])
self.embedding = EmbeddingLayer(features)
self.bottoms = nn.ModuleList(
MLP(self.input_dims, output_layer=False, **bottom_params) for i in range(self.n_task))
self.towers = nn.ModuleList(MLP(bottom_params["dims"][-1], **tower_params_list) for i in range(self.n_task))
self.info_gates = nn.ModuleList(
MLP(bottom_params["dims"][-1], output_layer=False, dims=[bottom_params["dims"][-1]])
for i in range(self.n_task - 1))
self.aits = nn.ModuleList(AttentionLayer(bottom_params["dims"][-1]) for _ in range(self.n_task - 1))
def forward(self, x):
embed_x = self.embedding(x, self.features, squeeze_dim=True) #[batch_size, *]
input_towers = [self.bottoms(embed_x) for i in range(self.n_task)] #:[batch_size, bottom_dims[-1]]
for i in range(1, self.n_task): #for task 1:n-1
info = self.info_gates[i - 1](input_towers[i - 1]).unsqueeze(1) #[batch_size,1,bottom_dims[-1]]
ait_input = torch.cat([input_towers.unsqueeze(1), info], dim=1) #[batch_size, 2, bottom_dims[-1]]
input_towers = self.aits[i - 1](ait_input)
ys = []
for input_tower, tower in zip(input_towers, self.towers):
y = tower(input_tower)
ys.append(torch.sigmoid(y))
return torch.cat(ys, dim=1)
class AttentionLayer(nn.Module):
def __init__(self, dim=32):
super().__init__()
self.dim = dim
self.q_layer = nn.Linear(dim, dim, bias=False)
self.k_layer = nn.Linear(dim, dim, bias=False)
self.v_layer = nn.Linear(dim, dim, bias=False)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
Q = self.q_layer(x)
K = self.k_layer(x)
V = self.v_layer(x)
a = torch.sum(torch.mul(Q, K), -1) / torch.sqrt(torch.tensor(self.dim))
a = self.softmax(a)
outputs = torch.sum(torch.mul(torch.unsqueeze(a, -1), V), dim=1)
return outputs |
|



 发表于 2022-12-12 14:01:06
发表于 2022-12-12 14:01:06

