|
|
标题:ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction
作者:Jiahao Bu, Lei Ren, Shuang Zheng, Yang Yang, Jingang Wang, Fuzheng Zhang, Wei Wu
来源:NAACL,2021
code:https://github.com/Meituan-Dianping/asap
1 Introduction
随着电子商务的快速发展,电子商务平台上的海量用户评论正在成为客户和商家的宝贵资源。基于方面的用户评论情感分析 (ABSA) 是一项基本且具有挑战性的任务,它吸引了学术界和工业界的兴趣(Hu 和 Liu,2004;Ganu et al,2009;Jo 和 Oh,2011;Kirichenko et al, 2014)。根据文本中是否明确提及方面术语,ABSA 可以进一步分类为方面词情感分析(ATSA) 和方面类别情感分析(ACSA),我们关注后者,后者在行业中应用更广泛。
在 ACSA 技术的帮助下,电子商务平台的用户界面比以往任何时候都更加智能。例如,图 1 显示了中国流行电子商务平台上一家咖啡店的详细信息页面。上面的基于方面的情感文本框显示了用户评论中经常提到的方面类别(例如,食物、卫生)以及这些方面类别上的汇总情感极性(橙色代表积极,蓝色代表消极)。客户可以通过点击他们关心的基于方面的情感文本框来有效地关注相应的评论(例如,橙色填充的文本框“卫生条件好”(良好的卫生条件))。我们基于 7, 824 份有效问卷的用户调查表明,80.08% 的客户同意基于方面的情感文本框有助于他们做出餐厅选择的决策。此外,商家可以借助基于方面的情感文本框来跟踪他们的美食和服务质量。大多数中国电子商务平台,如淘宝 、大众点评 和口碑都部署了类似的用户界面来改善用户体验。

用户还发布了他们的整体 5 星级评级以及评论。图 1 显示了咖啡店 5 星评级的示例。与细粒度的方面情绪相比,整体评论评级通常是对多个方面的意见的粗粒度综合。Rating prediction(RP)旨在预测评论“星级”(Jin et al., 2016; Li et al., 2018; Wu et al., 2019a)也有广泛的应用。例如,为了保证基于方面的情感文本框准确,应该在执行 ACSA 算法之前删除不可靠的评论。给定一条用户评论,我们可以根据文本背后的整体情感极性来预测它的评级。只要评论是可靠的,我们假设评论的预测评级应该与其真实评级一致。如果评论的预测评分和用户评分明显不一致,则评论的可靠性是值得怀疑的。图 2 展示了低可靠性的示例审查。综上所述,RP 可以帮助商家检测不可靠的评论。

因此,ACSA和RP对于电子商务中的商业智能都具有重要意义,并且具有高度的关联性和互补性。 ACSA 侧重于预测其在不同方面类别上的潜在情感极性,而 RP 侧重于从评论内容中预测用户的整体感受。我们认为这两个任务高度相关,通过联合考虑它们可以获得更好的性能。
据我们所知,目前的公共数据集是分别为 ACSA 和 RP 构建的,这限制了 ACSA 和 RP 的进一步联合探索。为了解决这个问题并推进相关研究,本文提出了一个用于Aspect category Sentiment Analysis and rating Prediction的大型中文餐馆评论数据集,简称为ASAP。 ASAP 中的所有评论均来自上述电子商务平台。附有 46, 730 条 5 星级评分的餐厅评论。每条评论都根据其对 18 个细粒度方面类别的情感极性进行手动注释。据我们所知,ASAP 是中国最大的针对 ACSA 和 RP 任务的大规模评论数据集。
我们为 ACSA 和 RP 复现了几个最先进的 (SOTA) 基线,并在 ASAP 上评估了它们的性能。为了进行公平比较,我们还在广泛使用的 SemEval-2014 餐厅评论数据集(Pontiki et al., 2014)上进行了 ACSA 实验。由于 BERT(Devlin et al,2018)在包括情感分析(Xu et al,2019;Sun et al,2019;Jiang et al,2019)在内的多项自然语言理解任务中取得了巨大成功,我们提出了一个联合模型,采用了 BERT 的从细到粗粒度语义能力。我们的联合模型在这两个任务上都优于竞争基线。
我们的主要贡献可以总结如下。
(1) 我们提出了一个大规模的中文评论数据集,用于方面类别情感分析和评分预测,命名为 ASAP,包括从 18 个预定义方面类别注释的多达 46,730 条真实的餐厅评论。
(2) 我们尽快探索广泛使用的 ACSA 和 RP 模型的性能。
(3) 我们为 ACSA 和 RP 任务提出了一个联合学习模型。我们的模型在 ASAP 和 SemEval RESTAURANT 数据集上都取得了最好的结果。
2 Related Work and Datasets
Aspect Category Sentiment Analysis.ACSA(Zhou et al., 2015; Movahedi et al., 2019; Ruder et al., 2016; Hu et al., 2018)旨在预测文本中提到的所有方面类别的情感极性。由电子商务网站的用户评论组成的一系列 SemEval 数据集已被广泛使用,并推动了相关研究(Wang et al., 2016; Ma et al., 2017; Xu et al., 2019; Sun et al., 2019;Jiang et al.,2019)。 SemEval-2014 task-4 数据集 (SE-ABSA14) (Pontiki et al., 2014) 由笔记本电脑和餐厅评论组成。餐厅子集包括 5 个方面类别(Food, Service, Price, Ambienc and Anecdotes/Miscellaneous)和 4 个极性标签(即Positive, Negative, Conflict and Neutral)。笔记本电脑子集不适合 ACSA。 SemEval-2015 task-12 数据集 (SE-ABSA15) (Pontiki et al., 2015) 建立在 SE-ABSA14 的基础上,并将其方面类别定义为实体类型和属性类型的组合(例如,Food#Style Options )。 SemEval2016 任务 5 数据集 (SE-ABSA16) (Pontiki et al., 2016) 将 SE-ABSA15 扩展到英语以外的新领域和新语言。 MAMS (Jiang et al., 2019) 定制 SE-ABSA14 使其更具挑战性,其中每个句子至少包含两个具有不同情感极性的方面。
与英语资源的繁荣相比,优质的中文数据集还不够丰富。 “ChnSentiCorp”(Tan 和 Zhang,2008)、“IT168TEST”(Zagibalov 和 Carroll,2008)、“Weibo"、“CTB”(Li et al.,2014)是 4 个用于通用情感分析的流行中文数据集。但是,这些数据集中没有标注方面类别信息。Zhao et al.(2014) 提出了两个用于消费电子产品(手机和相机)的中文ABSA 数据集。然而,这两个数据集仅包含 400 个文档(~ 4000 个句子),其中每个句子最多只提到一个方面类别。 BDCI5 汽车意见挖掘和情感分析数据集(Dai et al., 2019)包含汽车行业的 8, 290 条用户评论,有 10 个预定义类别。Peng et al.(2017)总结了可用的中文ABSA数据集。虽然它们中的大多数是通过基于规则或基于机器学习的方法构建的,但这不可避免地会在数据集中引入额外的噪声。我们的 ASAP 在数量和质量上都优于中国数据集。
Rating Prediction.评分预测(RP)旨在预测评论的“星级”,代表评论的整体评分。与细粒度的方面情感相比,总体评价评分通常是多方面意见的粗粒度综合。Ganu et al.,(2009);Li et al.,(2011);Chen et al.,(2018)将此任务形成为文本分类或回归问题。考虑到评论中多方面意见的重要性,近年来有大量工作(Jin et al,2016;Cheng et al,2018;Li et al,2018;Wu et al,2019a)利用方面的信息提升评分预测的性能。这种趋势也激发了 ASAP 的动力。
大多数 RP 数据集都是从现实世界的评论网站上抓取的,并专门为 RP 创建。包含来自亚马逊的产品评论和元数据的亚马逊产品评论英文数据集(McAuley 和 Leskovec,2013 )已被广泛用于 RP(Cheng et al,2018 ;McAuley 和 Leskovec,2013 )。另一个流行的英语数据集来自 Yelp Dataset Challenge 2017,其中包括对 4 个国家/地区 12 个大都市地区本地企业的评论。 Openrice 是由 168,142 条评论组成的中文 RP 数据集。英文和中文数据集都没有标注细粒度的方面类别情感极性。
3 Dataset Collection and Analysis
3.1 Data Construction & Curation
我们从中国最受欢迎的 O2O 电子商务平台之一收集评论,该平台允许用户发布粗粒度的星级评分,并对他们访问过的餐厅(或景点)撰写细粒度的评论。在评论中,用户或明或暗地评论多个方面,包括环境、价格、食物、服务等。
首先,我们从拥有 50 多个用户评论的热门餐厅中随机检索大量用户评论。然后,执行 4 个预处理步骤以保证评论的道德、质量和可靠性。 (1) 出于隐私考虑,删除用户信息(例如,用户 ID、用户名、头像和发布时间)。 (2)过滤掉50字以下的短评,以及1000字以上的长评。 (3)如果评论中非汉字的比例超过70%,则该评论被丢弃。 (4)检测低质量评论(例如广告文本),我们构建了一个基于 BERT 的分类器,在遗漏测试集中准确率为 97%。分类器检测为低质量的评论也会被丢弃。
3.2 Aspect Categories
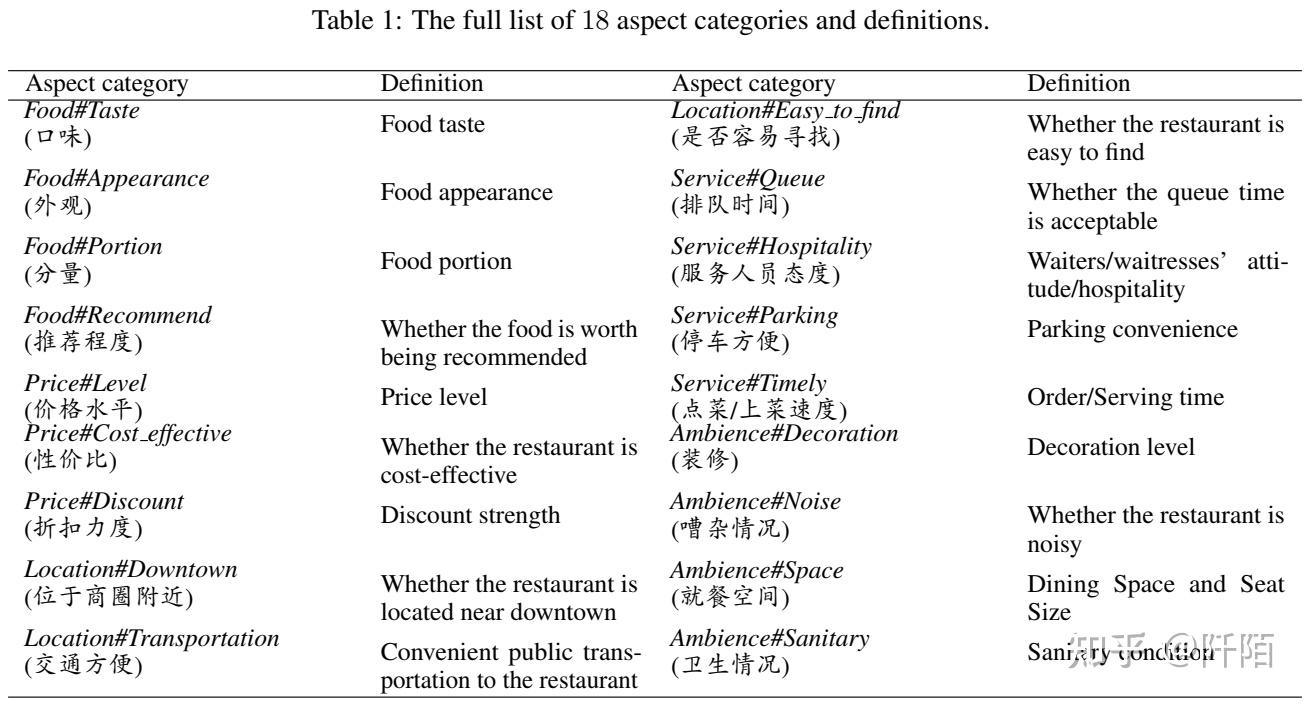
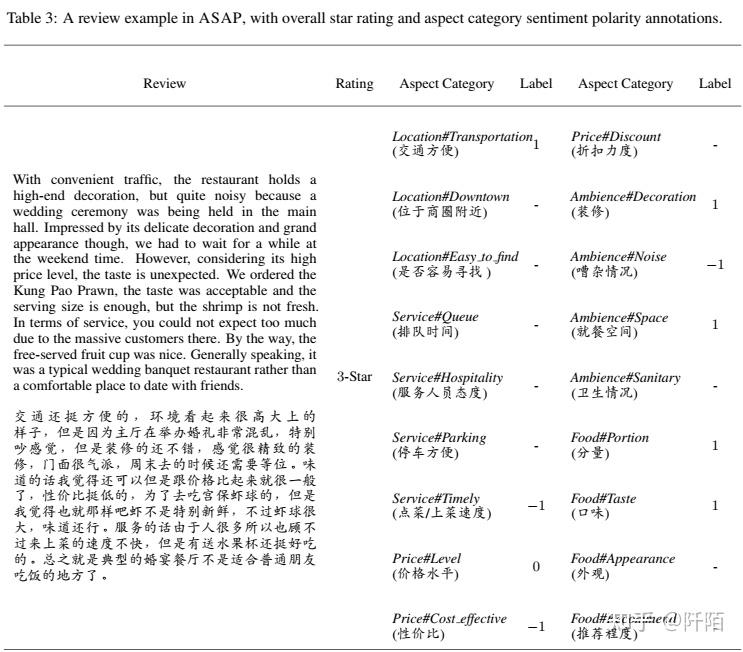
由于评论已经包含用户的星级,本节主要介绍我们对 ACSA 的注释细节。在 SE-ABSA14 餐厅数据集(为简单起见,表示为 RESTAURANT),有 5 个粗粒度的方面类别,包括food, service, price, ambience and miscellaneous.在对收集到的评论进行深入分析后,我们发现用户提到的方面类别相当多样化和细粒度。以表 3 中文本为例“....The restaurant holds a high-end decoration but is quite noisy since a wedding ceremony was being held in the main hall... (...环境看起来很大上的样子,但因为主厅在婚礼上举办的特别混乱,感觉很吵……)”,评论人实际上在与环境相关的两个细粒度方面类别上表达了相反的情感极性。餐厅的装修非常高档(正面),但由于正在进行的仪式而非常嘈杂(负面)。因此,我们总结了经常提到的方面,并将 5 个粗粒度类别细化为 18 个细粒度类别。我们将miscellaneous替换为location,因为我们发现用户通常会查看餐厅的位置(例如,该餐厅是否可以通过公共交通工具轻松到达。)。我们将方面类别表示为“Coarse-grained Category#Fine-grained Categoty”的形式,例如“Food#Taste”和“Ambience#Decoration”。方面类别和定义的完整列表列于表 1。
3.3 Annotation Guidelines & Process
牢记预定义的 18 个方面,要求评估者针对每个评论的上述方面类别注释情感极性。给定评论,当评论中明确或隐含地提及某个方面类别时,该方面类别上的情感极性标记为 1(正面)、0(中性)或 -1(负面),如表 3 所示。
我们聘请了 20 名供应商评估员、2 名项目经理和 1 名专家评审员来执行注释。每个评估员都需要参加培训,以确保他们完全理解注释指南。依次进行三轮注释。首先,我们将整个数据集随机分成 10 组,每组分配给 2 名评估员进行独立注释。其次,根据标注结果将每组分成2个子集,分别表示为Sub-Agree和SubDisagree。 Sub-Agree 包括带有同意注释的数据示例,而 Sub-Disagree 包括带有不同意注释的数据示例。子协议将由其他组的评估员进行审查。审查期间有争议的例子被视为疑难案例。 Sub-Disagree 将由 2 位项目经理独立审核,然后讨论达成一致的注释。经讨论无法解决的例子也被视为疑难案例。第三,对于每个组,将来自两个子集的困难示例交付给专家评审员做出最终决定。表 2 展示了注释过程中的困难案例和注释指南的更多细节。

最后,ASAP 语料库由 46,730 条真实用户评论组成,我们将其随机分为训练集 (36, 850)、验证集 (4, 940) 和测试集 (4, 940)。表 3 给出了 ASAP 的示例回顾以及 18 个方面类别的相应注释。
3.4 Dataset Analysis
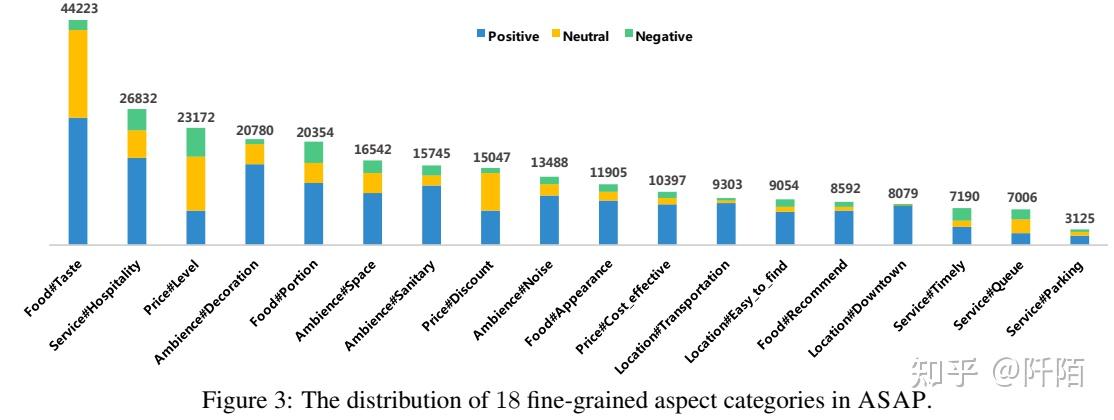
图3展示了 ASAP 中 18 个方面类别的分布。由于 ASAP 专注于餐厅领域,因此 94.7% 的评论如预期提及 F ood#Taste。用户也非常关注服务#热情好客、价格#级别和氛围#装饰等方面的类别。分布证明了ASAP的优势,用户细粒度的偏好可以更准确地反映餐厅的优劣。
ASAP 的统计数据如表 4 所示。我们还包括一个定制的 SE-ABSA14 RESTAURANT 数据集以供参考。请注意,我们从原始 RESTAURANT 数据集中删除了包含具有“冲突”情感极性的方面类别的评论。
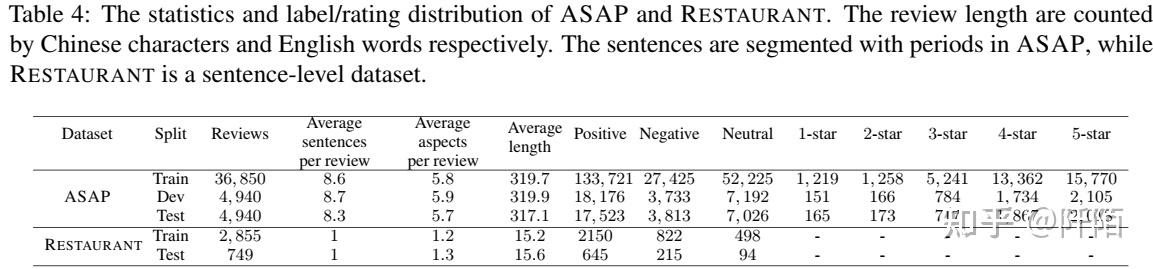
与 RESTAURANT 相比,ASAP 在训练实例的数量上更胜一筹,这支持了对近期数据密集型深度神经模型的探索。 ASAP 是一个评论级别的数据集,而 RESTAURANT 是一个句子级别的数据集。 ASAP 中评论的平均长度要长得多,因此评论往往包含更丰富的方面信息。在ASAP,评论平均包含5.8个方面类别,是RESTAURANT的4.7倍。评论级的 ACSA 和 RP 都比句子级别更具挑战性。以表 3 中的评论为例,该评论包含多个面向多个方面类别的情绪极性。除了方面类别情感注释,ASAP 还包括评论的总体用户评分。在 ASAP 的帮助下,ACSA 和 RP 可以单独或联合进一步优化。
4 Methodology
4.1 Problem Formulation
我们使用 D 表示训练数据中用户评论语料库的集合。给定由一系列单词组成的评论 R:{w1, w2, ..., wZ},ACSA 旨在预测评论 R 的情感极性 yi ∈ {Positive, Neutral, Negative}提到的方面类别 ai, i ∈ {1, 2, ..., N}。 Z 表示评论 R 的长度。N 是预定义的方面类别的数量(即本文中的 18 个)。假设 R 中有 K 个提到的方面类别。我们定义一个掩码向量 [p1, p2, ..., pN] 来指示方面类别的出现。当R中提到aspect category ai时,pi = 1,否则pi = 0。所以我们有PN i=1 pi = K。就RP而言,它旨在预测g的5星评分,它表示给定评论 R 的总体评分。
4.2 Joint Model
给定用户评论,ACSA 侧重于预测其在不同方面类别上的潜在情感极性,而 RP 侧重于从评论内容中预测用户的整体感受。我们认为这两个任务高度相关,通过联合考虑它们可以获得更好的性能。
BERT 的出现为 NLP 任务确立了“先训练后微调”范式的成功。基于 BERT 的模型在 ACSA 中取得了令人瞩目的成果(Xu et al,2019;Sun et al,2019;Jiang et al,2019)。评论评分预测可以被视为单句分类(回归)任务,也可以通过 BERT 来解决。因此,我们提出了一种联合学习模型,以多任务学习的方式解决 ACSA 和 RP。我们的联合模型采用了 BERT 编码器从精细到粗糙的语义表示能力。图 4 说明了我们的联合模型的框架。
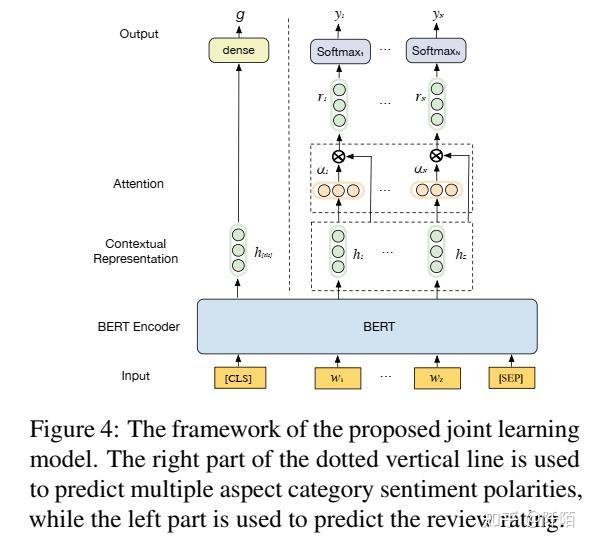
ACSA 如图 4 所示,输入评论的词嵌入是通过共享的 BERT 编码器生成的。简而言之, H ∈ Rd∗Z 是由 BERT 生成的词嵌入向量 {h1, ..., hZ} 组成的矩阵,其中 d 是隐藏层的大小,Z 是给定评论的长度。由于不同的方面类别信息分散在 R 的内容中,我们添加了一个注意力池层 (Wang et al., 2016) 来动态聚合每个方面类别的相关词嵌入。注意力池层帮助模型关注与目标方面类别最相关的标记。
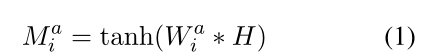
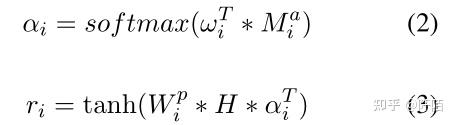
其中 Wai ∈ Rd∗d, Mai ∈ Rd∗Z, ωi ∈ Rd, αi ∈ RZ, W pi ∈ Rd∗d, and ri ∈ Rd. αi 是一个向量,由所有标记的注意力权重组成,这些标记可以选择性地关注与方面类别相关的标记的区域,ri 是关于第 i 个方面类别 ai 的评论的注意力表示,i ∈ {1, 2, .. ., N}。然后我们有
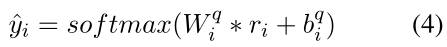
其中 W qi ∈ RC∗d 和 bqi ∈ RC 是 softmax 层的可训练参数。 C 是标签的数量(即我们的任务中的 3 个)。因此,给定评论 R 的 ACSA 损失定义如下:
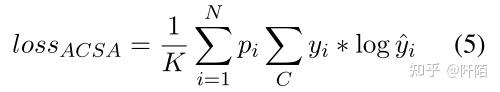
如果 S 中没有提到方面类别 ai,则将 yi 设置为随机值。 pi 作为gate函数,过滤掉随机的 yi,确保只有提到的方面类别才能参与损失函数的计算。
Rating Prediction:由于 RP 的目标是根据评论内容预测评论评分,我们采用BERT 生成的 [CLS]嵌入 h[cls] ∈ Rd 作为输入评论的表示,其中 d 是隐藏层的大小BERT 编码器。
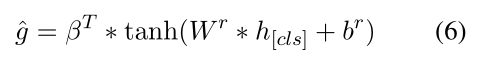
因此,给定评论 R 的 RP 损失定义如下,
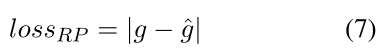
我们的联合模型的最终损失如下。
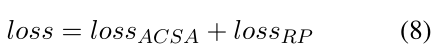
5 Experiments
我们进行了大量的实验来评估我们的联合模型在 ASAP 和 RESTAURANT 上的性能(Pontiki et al., 2014)。还进行消融研究以探讨 ACSA 和 RP 之间的交互影响。
5.1 ACSA
Implementation Details of Experimental Models:
对于非基于 BERT 的模型,我们使用预训练的嵌入来初始化它们的输入。对于中文 ASAP,我们利用 Jieba 对中文文本进行分割,并采用由 8,000,000 个词组成的腾讯中文词嵌入(Song et al., 2018)。对于英语 RESTAURANT,我们采用 Glove 预训练的 300 维词嵌入(Pennington et al,2014)。
在基于 BERT 的模型方面,我们采用 12 层 Google BERT Base 对输入进行编码。
对于非基于 BERT 的模型和基于 BERT 的模型,批量大小分别设置为 32 和 16。使用 Adam 优化器(Kingma 和 Ba,2014),β1 = 0.9 和 β2 = 0.999。最大序列长度设置为 512。epoch 数设置为 3。非基于 BERT 的模型和基于 BERT 的模型的学习率分别设置为 0.001 和 0.00005。所有模型都在单个 NVIDIA Tesla 32G V100 Volta GPU 上进行训练。
Evaluation Metrics:
按照RESTAURANT的设置,我们采用Macro-F1和Accuracy 作为评价指标。
Experimental Results & Analysis
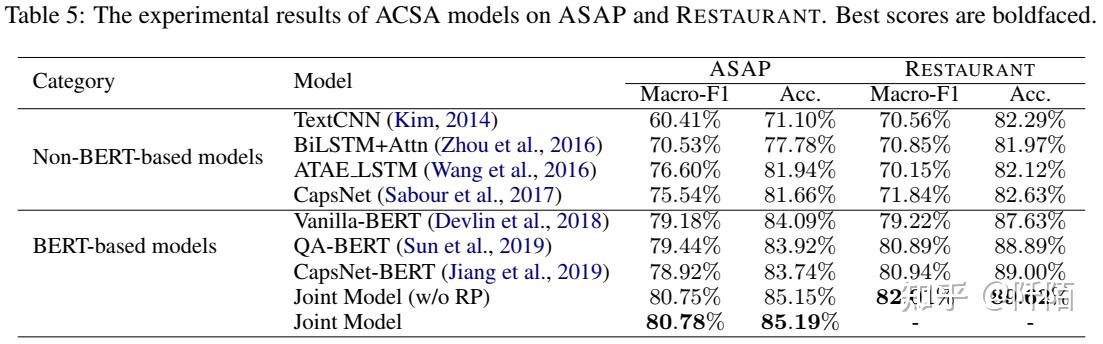
我们在表 5 中报告了上述模型在 ASAP 和 RESTAURANT 上的性能。通常,基于 BERT 的模型在两个数据集上都优于基于非 BERT 的模型。我们联合模型的两个变体比 vanilla-BERT、QABERT 和 CapsNet-BERT 表现更好,这证明了我们联合学习模型的优势。给定用户评论,vanilla-BERT、QA-BERT 和 CapsNetBERT 独立处理预定义的方面类别,而我们的联合模型将它们与多任务学习框架结合在一起。一方面,编码器共享设置可以实现不同方面类别之间的知识转移。另一方面,我们的联合模型比其他竞争对手更有效,尤其是当方面类别的数量很大时。 RP 的消融(即联合模型(w/o RP))仍然优于所有其他基线。将 RP 引入 ACSA 带来了边际改进。考虑到 RP 的基本目标是估计整体情绪极性而不是细粒度的情绪极性,这是合理的。
我们在图 5 中的表 3 的示例中可视化我们的联合模型产生的注意力权重。由于不同的方面类别信息分散在 R 的评论中,我们添加了一个注意力池层 (Wang et al., 2016) 来聚合每个方面类别的相关令牌嵌入动态。注意力池层帮助模型关注与目标方面类别最相关的标记。图 5 可视化了 3 个给定方面类别的注意力权重。颜色的强度表示注意力权重的大小,这意味着标记与给定方面类别的相关性。很明显,我们的联合模型专注于与 R 评论中的方面类别最相关的标记。

5.2 Rating Prediction
我们在 ASAP 上比较了几个 RP 模型,包括 TextCNN (Kim, 2014)、BiLSTM+Attn (Zhou et al., 2016) 和 ARP (Wu et al., 2019b)。数据预处理和实现细节与 ACSA 实验相同。
Evaluation Metrics.
我们采用平均绝对误差 (MAE) 和Accuracy(通过将预测评分映射到最近的类别)作为评估指标。
Experimental Results & Analysis
比较 RP 模型的实验结果如表 6 所示。
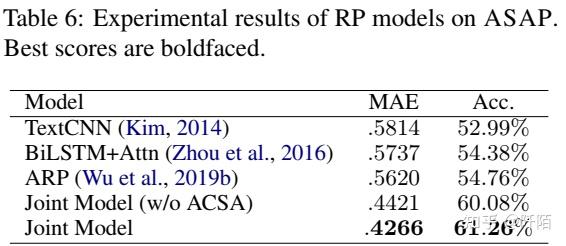
我们结合 ACSA 和 RP 的联合模型大大优于其他模型。一方面,由于我们的联合模型是建立在 BERT 之上的,因此性能提升是可以预期的。另一方面,ACSA 的消融(即联合模型(w/o ACSA))导致 RP 在两个指标上的性能下降。我们可以得出结论,评论的细粒度方面类别情感预测确实有助于模型更准确地预测其整体评分。
本节进行初步实验,以评估我们提出的 ASAP 数据集上的经典 ACSA 和 RP 模型。我们相信这两项任务仍有很大的改进空间,我们将把它们留给未来的工作。
6 Conclusion
本文介绍了 ASAP,一个面向方面类别情感分析 (ACSA) 和评级预测 (RP) 的大型中文餐馆评论数据集。 ASAP 包含来自中国领先电子商务平台的 46,730 条餐厅用户评论和星级评分。每条评论都根据其在 18 个细粒度方面类别上的情感极性进行手动注释。除了分别在 ASAP 上评估 ACSA 和 RP 模型外,我们还提出了一个联合模型来综合处理 ACSA 和 RP,其性能大大优于其他最先进的基线。我们希望ASAP的发布能够推动相关研究和应用。 |
|



 发表于 2022-9-20 17:19:15
发表于 2022-9-20 17:19:15

