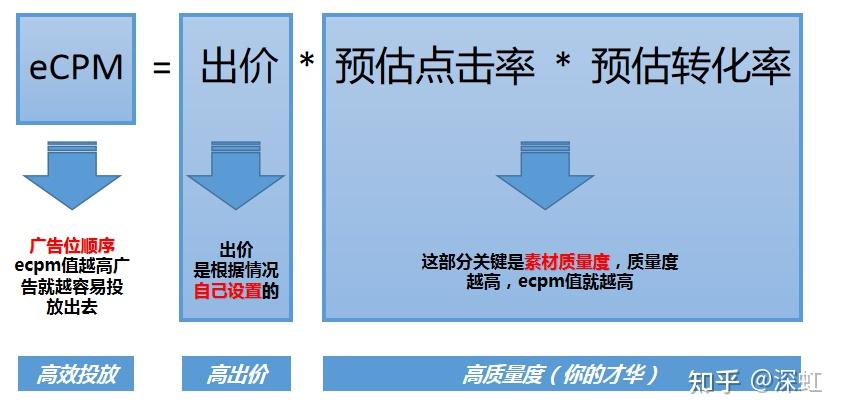
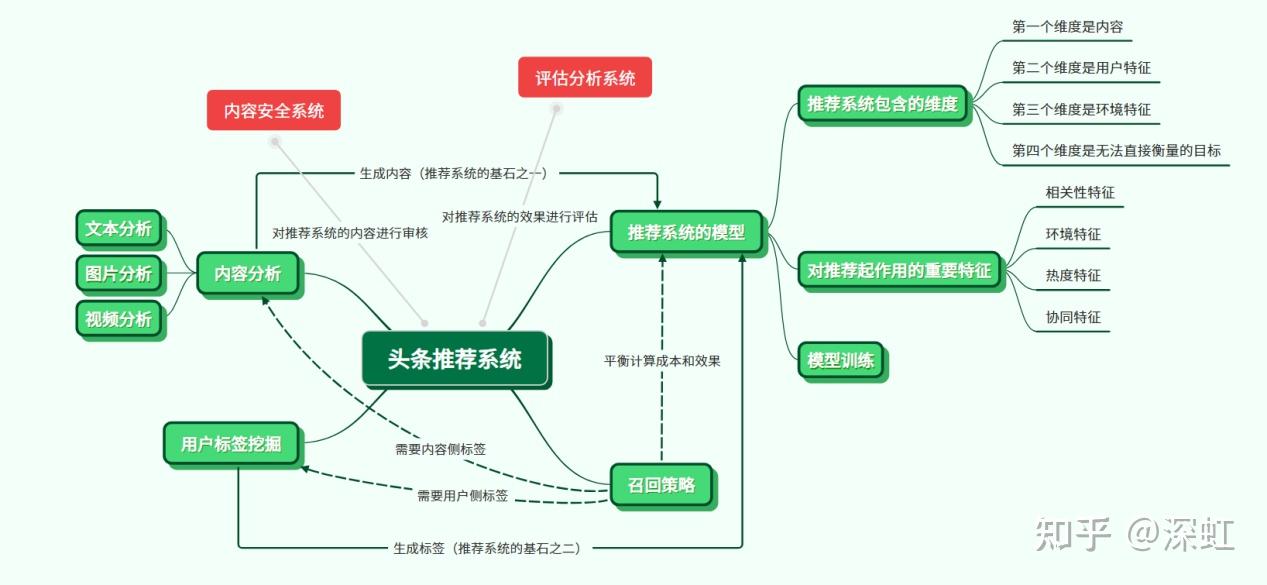
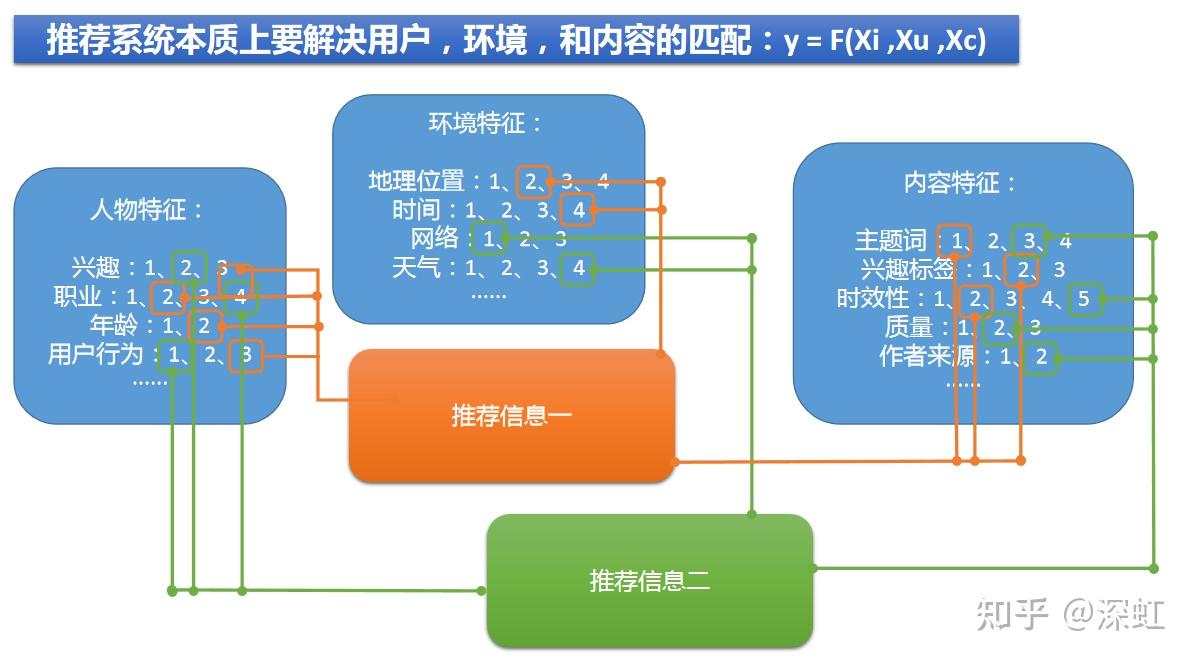
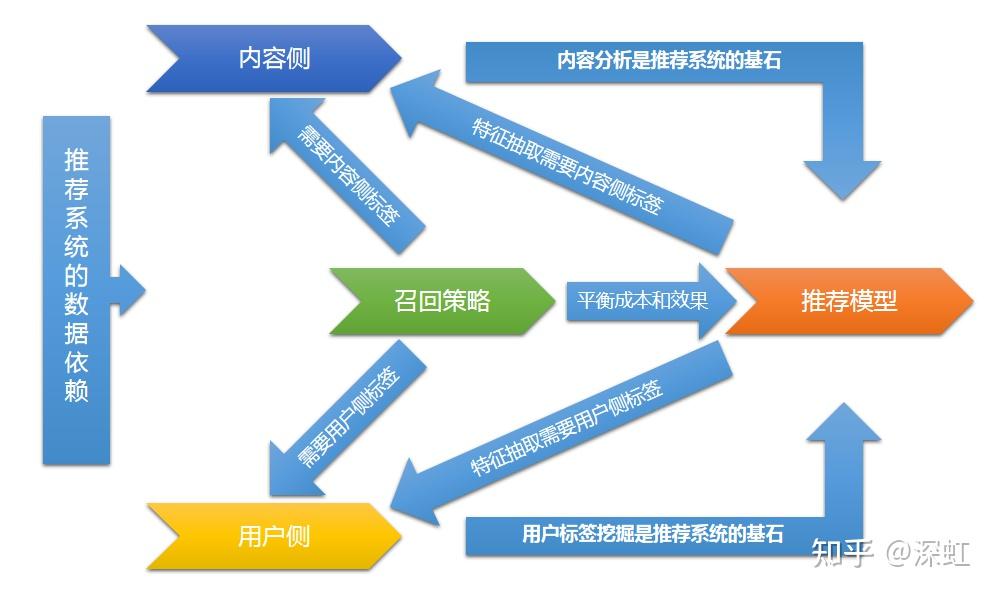
2
6
新手上路
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
了解好孕帮
联系好孕帮
加入好孕帮
好孕帮移动网站
新浪微博
生殖医学空间
官方微信公众号
医学备孕服务平台
好孕帮企业店
好孕帮官方店
添喜年官方旗舰店
好孕帮客服电话
周一至周日 9:30-19:00
(仅收市话费)
Archiver手机版
Powered by Discuz! X3.4© 2001-2015 Comsenz Inc.



 发表于 2022-9-23 18:39:25
发表于 2022-9-23 18:39:25